因业务需要,要实现某网站的模拟登录,涉及一个相对简单的图片验证码。
之前的登录方案,同事采用的基本都是 JS 逆向。然而逆向的工作量较大,因此尝试了另一种思路来解决这个问题。
出于隐私考虑,网站名称不便透露,这里仅展示部分测试数据。
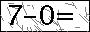

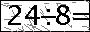
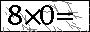
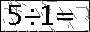
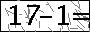
思路:
首先参考商业化解决方案,了解图片验证码的常见处理方式。
百度搜索”图像识别”、”图像文本识别”等关键词,出现了阿里云和腾讯云的广告,有一个关键词频繁出现:OCR。进一步搜索 OCR(Optical Character Recognition,光学字符识别),这是一个成熟的技术方向。在 GitHub 搜索该关键词,找到了现成的开源项目。
该项目使用 C++ 编写,支持 Windows/Linux 平台,可通过 CLI 操作并指定输出路径。安装后进行测试。
使用画图工具手写了几个算式,识别效果良好。然而直接用目标网站的图片识别效果不佳。
分析原因:第一,图片内容存在问题,可以看上面的测试数据集,存在较多干扰线。第二,Tesseract 的配置需要优化,虽然未识别出任何内容,但结果是一个四行的空文档。针对后者查阅 Tesseract 文档,发现有一个配置项 --psm,用于预指定识别模式,选择模式 13(单行识别模式)。针对前者,本版本采用了简单的图像预处理。
因此,整体处理模块分为两个部分:第一,图像去干扰;第二,调用 OCR 生成结果并处理。
一、图像去干扰
该图片集本身相对简单(这也是能够实现的原因,思路可供参考)。
分析图片特征:第一,图片四周存在单像素的干扰信息,呈现为黑框。第二,图片中的干扰像素和信息像素颜色区分度较高,信息像素基本偏向黑色,虽然不完全是 #000000,但 RGB 值普遍小于干扰像素。因此设置一个阈值,筛选出不够黑的像素点,直接涂白处理。
具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| const getPixels = require('get-pixels')
const fs = require('fs')
const jpeg = require('jpeg-js')
const { exec } = require('child_process')
const detach = 30
let pic = 'math'
process.argv[2] && (pic += process.argv[2])
const solve = () => {
getPixels(`${pic}.jpeg`, (err, pixels) => {
if (err) {
return
}
let x = pixels.shape[0]
let y = pixels.shape[1]
for (let i = 0 ; i < x ; i++) {
for (let j = 0 ; j < y ; j++) {
let r = pixels.get(i, j, 0)
let g = pixels.get(i, j, 1)
let b = pixels.get(i, j, 2)
if (r > detach || g > detach || b > detach || i === 0 || j === 0 || i === (x - 1) || j === (y - 1)) {
pixels.set(i, j, 0, 255)
pixels.set(i, j, 1, 255)
pixels.set(i, j, 2, 255)
}
}
}
let temp = {
width: x,
height: y,
data: pixels.data
}
fs.writeFileSync('./out.jpeg', jpeg.encode(temp).data)
})
}
|
去干扰前后对比
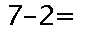
二、调用 OCR 处理
Windows 下的安装包下载地址。
安装过程按提示操作即可,安装完成后需手动设置环境变量。
Linux 用户请参考官方文档进行安装。
对应代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| const ocr = () => {
exec('tesseract out.jpeg out --psm 13', () => {
const s = fs.readFileSync('./out.txt').toString('utf8')
let res
let nums = s.match(/\d+/g)
if (s.match(/\+/)) {
res = Number(nums[0]) + Number(nums[1])
} else if (s.match(/-/)) {
res = Number(nums[0]) - Number(nums[1])
} else if (s.match(/x/)) {
res = Number(nums[0]) * Number(nums[1])
} else if (s.match(/÷/)) {
res = Number(nums[0]) / Number(nums[1])
}
console.log(res)
})
}
|
测试发现两个问题:乘号被识别为小写字母 x,可以通过正则匹配处理;除号基本无法识别,这需要更深入的解决方案。好在识别失败的影响不大,可以重新调用接口。
本篇文章到此结束。下一期计划尝试训练 Tesseract 训练集,专门优化乘号、除号的识别问题。
Update (2025): 由于业务需求变更,本文原计划的下篇(Tesseract 训练集优化)未能完成。不过本文介绍的图像预处理 + OCR 识别的基本思路仍具有参考价值。